Brindamos Servicio de Diseño Web a Todo México, desde Xalapa, Veracruz.
Solución Todo En Uno
Solucionamos tus necesidades en el diseño de paginas web que necesitas, Wordpress, Tiendas Online, Catálogos en Linea y cualquier otro tipo de sitio web dinámico o estático.
Nos adaptamos a tu Presupuesto
Tenemos un plan de trabajo que seguramente se adapta a tu presupuesto y a tus necesidades de desarrollo web o gráfico.
Sitios web con diseño Responsive
Todos nuestros diseños de sitios web son totalmente adaptables a los dispositivos móviles, para poder llegar a la mayor audiencia posible.
Soporte Directo
Servicio de soporte personalizado y siempre en contacto con nuestros clientes. Despejaremos todas tus dudas con respecto a tu proyecto web o gráfico.
Pasión por lo Original
Nos encanta nuestro trabajo. Cada uno de nuestros proyectos de diseño web o gráfico es único y original cumpliendo con las expectativas de nuestros clientes.
Sin Cuotas Extra
Respetamos lo que especificamos en nuestras cotizaciones y por supuesto en nuestros contratos, !así es¡, firmamos un contrato contigo para garantizar que no habrá nada oculto.
Profesionales del diseño web siempre a tu disposición.
Diseño de Sitios Web Profesionales y Originales.
El Diseño de Paginas Web así como el marketing digital forman parte de nuestra especialidad junto con Wordpress, ayudamos a que nuestros clientes transmitan su imagen y objetivos de manera tal que generen valor a sus negocios o proyectos. Recuerda si buscas un diseño de tu pagina web creativa o crear una tienda virtual en Xalapa, en Veracruz, en CDMX o en todo México, piensa en JuCri – WebDesign .
En cada pagina web y tienda en linea que creamos ponemos todo el espíritu creativo para tener así un diseño web original y único que convierta conceptos y palabras en diseños que reflejan el espíritu de una empresa, la pureza y grandeza de una marca, el objetivo de una organización o las aspiraciones de un individuo. ¡ Hecha un Ojo a Nuestros Planes de Diseño de Paginas Web !
Algunos de Nuestros Clientes














Algunos de Nuestros Clientes
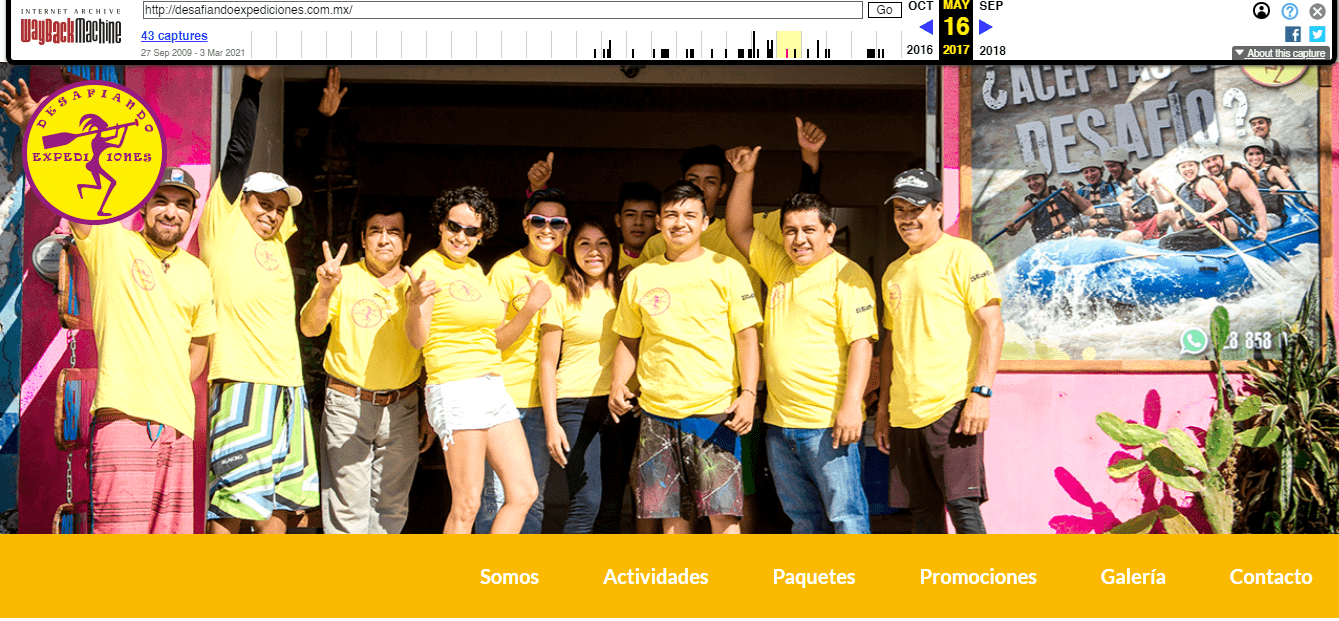
Diseño Web - Desafiando Expediciones
Diseño Web - Materiales Vasquez
Diseño Web - Rapidos Veracruz
Diseño Web - Greentech
Diseño Web - Artesanías Web
Diseño Web - Cinacatla
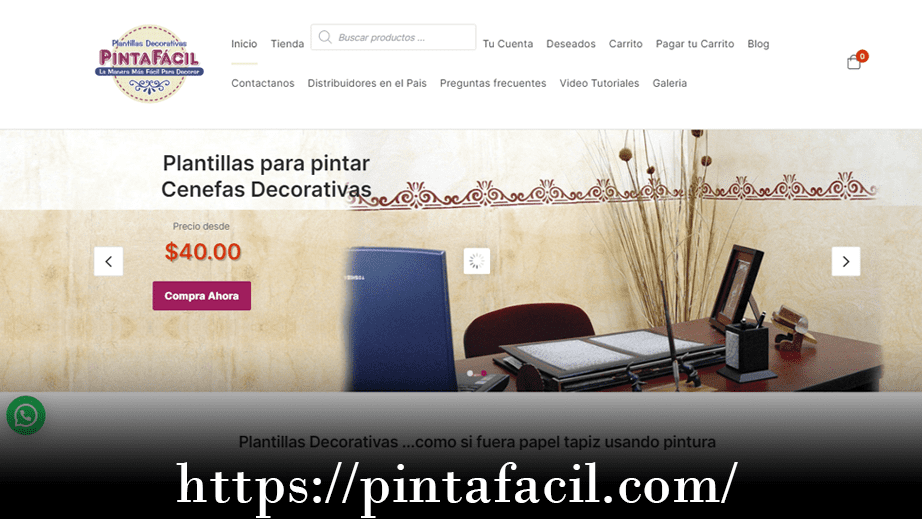
Diseño Web - Pintafacil
Diseño Web - Qualisa
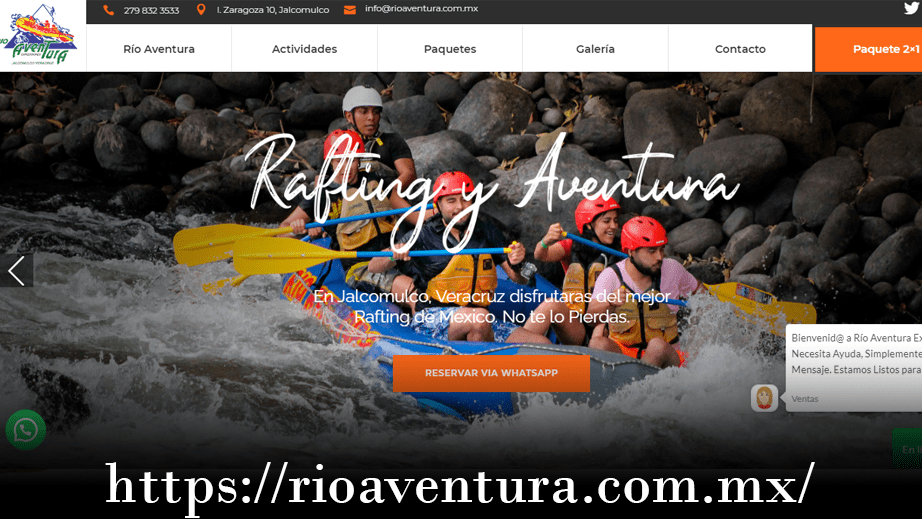
Diseño Web - Rio Aventura
Diseño Web - Diseño de Paginas Web Mexico
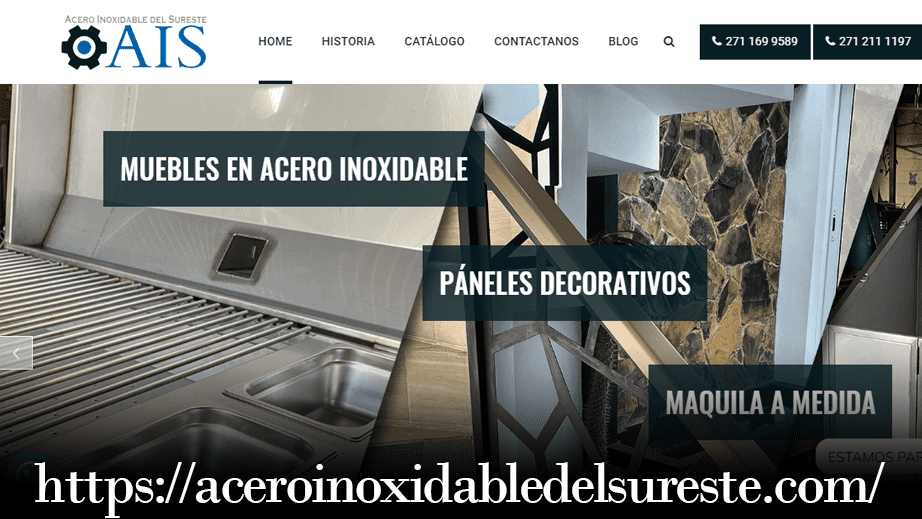
Diseño Web - Acero Inoxidable
Diseño Web - Ayuntamiento Tlaltetela
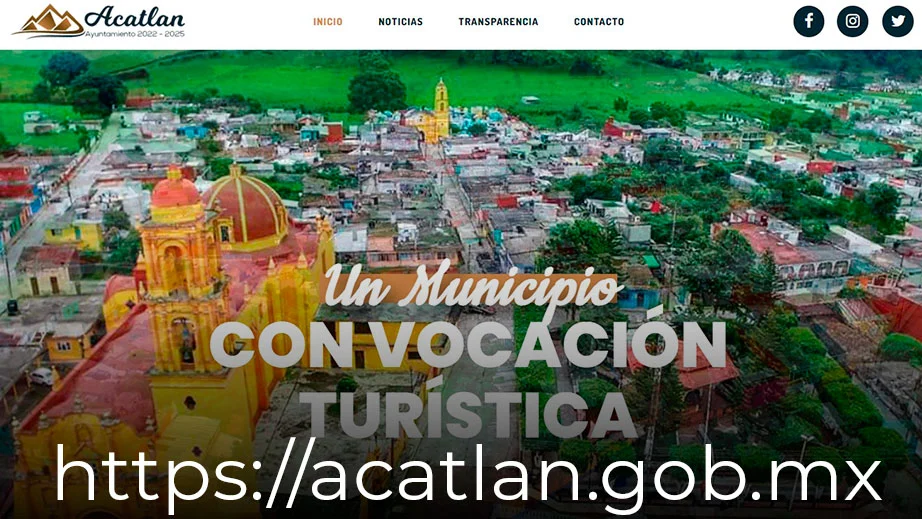
Diseño Web - Ayuntamiento Acatlan
Diseño Web - La Casita Organica
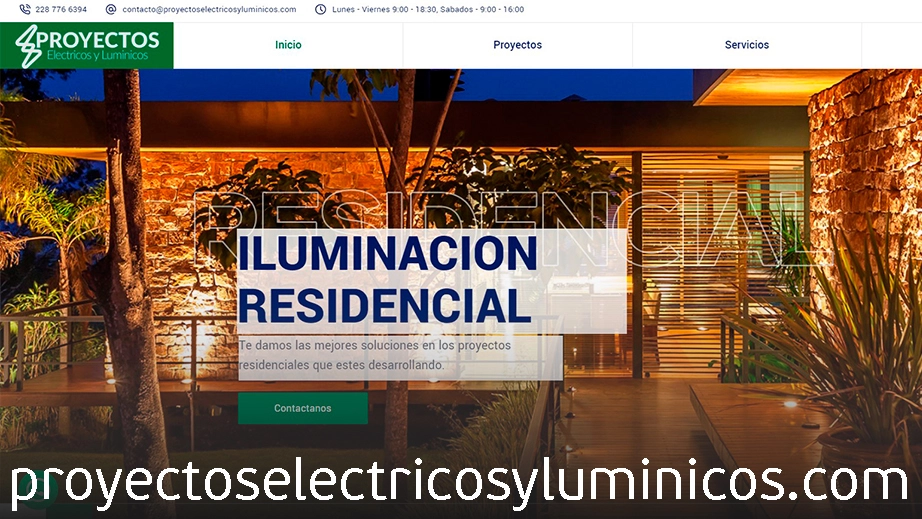
Diseño Web - Proyectos Electricos y Luminicos
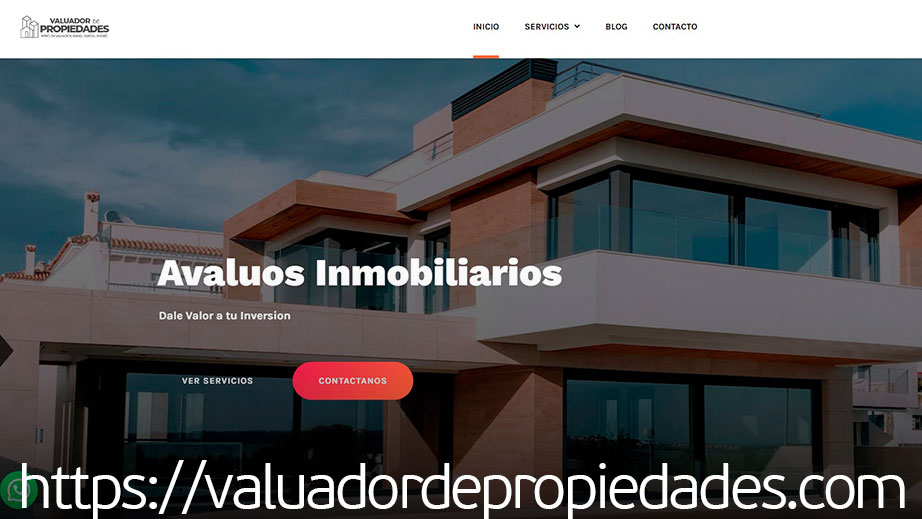
Diseño Web - Valuador de Propiedades
Diseño Web - Cotlamani
Diseño Web - Cementos Tajin
Diseño Web - SimpleBlueFrog Texas
Diseño Web - OPEV
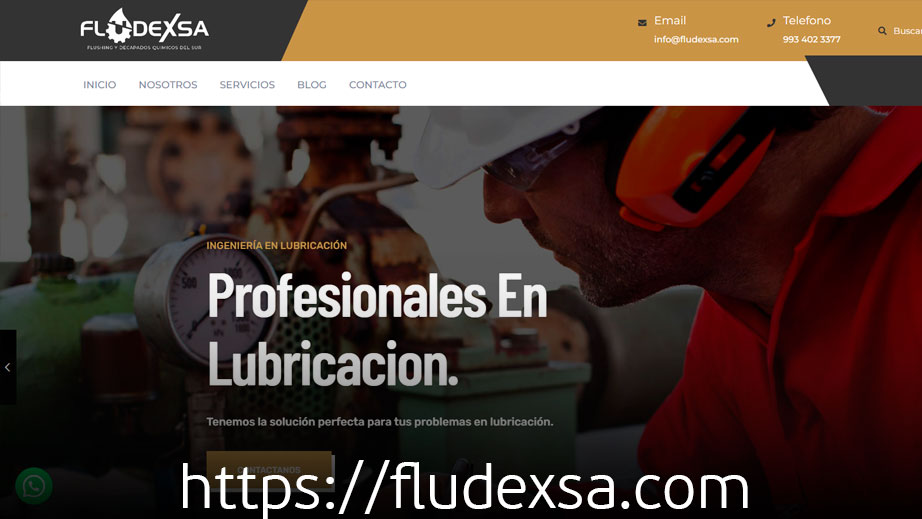
Diseño Web - Fludexsa
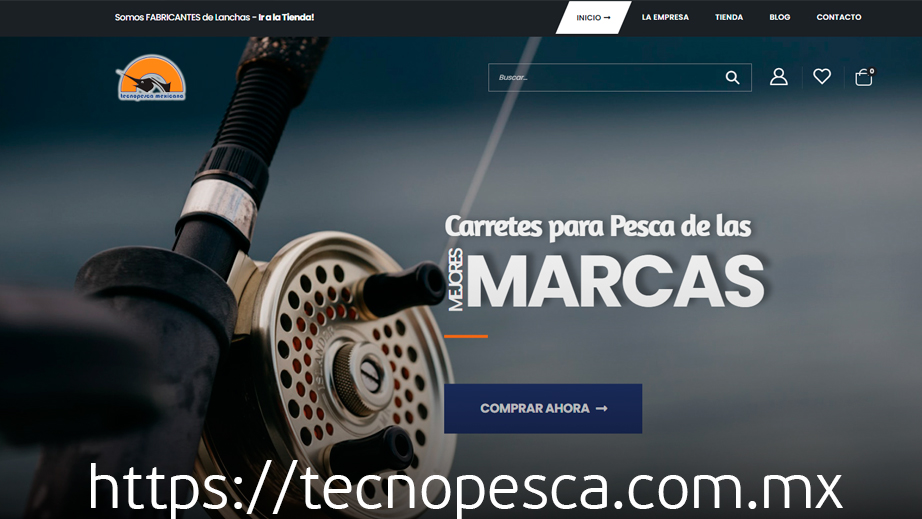
Diseño Web - Tecnopesca Mexicana
¿No Tienes Presencia en Internet?
Cotiza tu Diseño Web y Sumate a las Ventajas de vender en Línea.
El Diseño de Paginas Web es Nuestra Pasion.
Diseño web de calidad es el centro de nuestro negocio y servicios.EL diseño de paginas web en Veracruz
El diseño de páginas web en Veracruz, en Xalapa y en CDMX es un servicio que ha tenido mucha demandada por lo que han surgido diseñadores express, nosotros llevamos más de 15 años de experiencia en el servicio y sabremos dar solución a tu necesidad.
Somos especialistas en proyectos de diseño de paginas web profesionales de alta calidad donde la presentación profesional de la organización o negocio que nos contrata es primordial. Ayudamos a crear negocios desde cero con una mezcla de marketing digital, brindamos soluciones de diseño creativo e Integral.
¿Por que trabajar con JuCri?
Ofrecemos un servicio completo que realmente se asocia con nuestros clientes para lograr resultados eficientes. Diseñamos sitios web que aumentan la rentabilidad de los negocios a través de su pagina web como un canal mas de ventas.
Contamos con un servicio de hosting y de compra de dominio, lo que nos permite cuidar todos los aspectos de su sitio web para que no tenga que involucrarse con ningún detalle técnico. Simplemente déjenos hacer el trabajo de la red para usted.
EL ANTES y el DESPUES - Sitios Web Diseñados
Diseño Web Greentech (Desliza el Tirador)


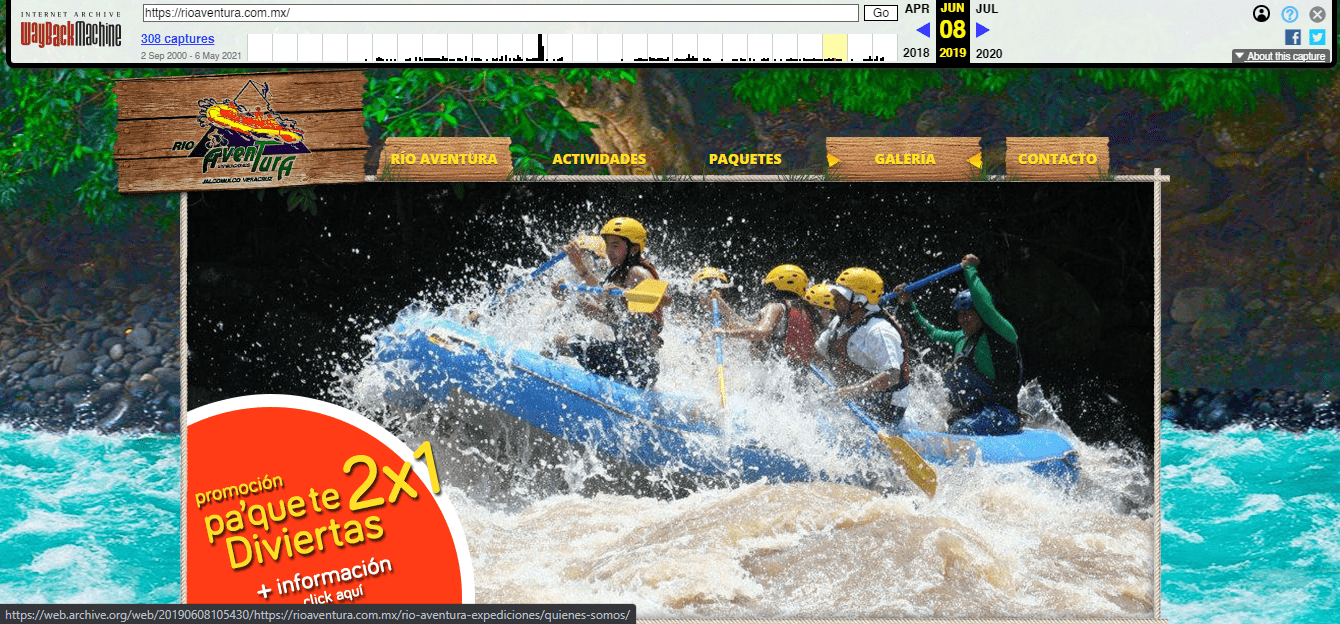
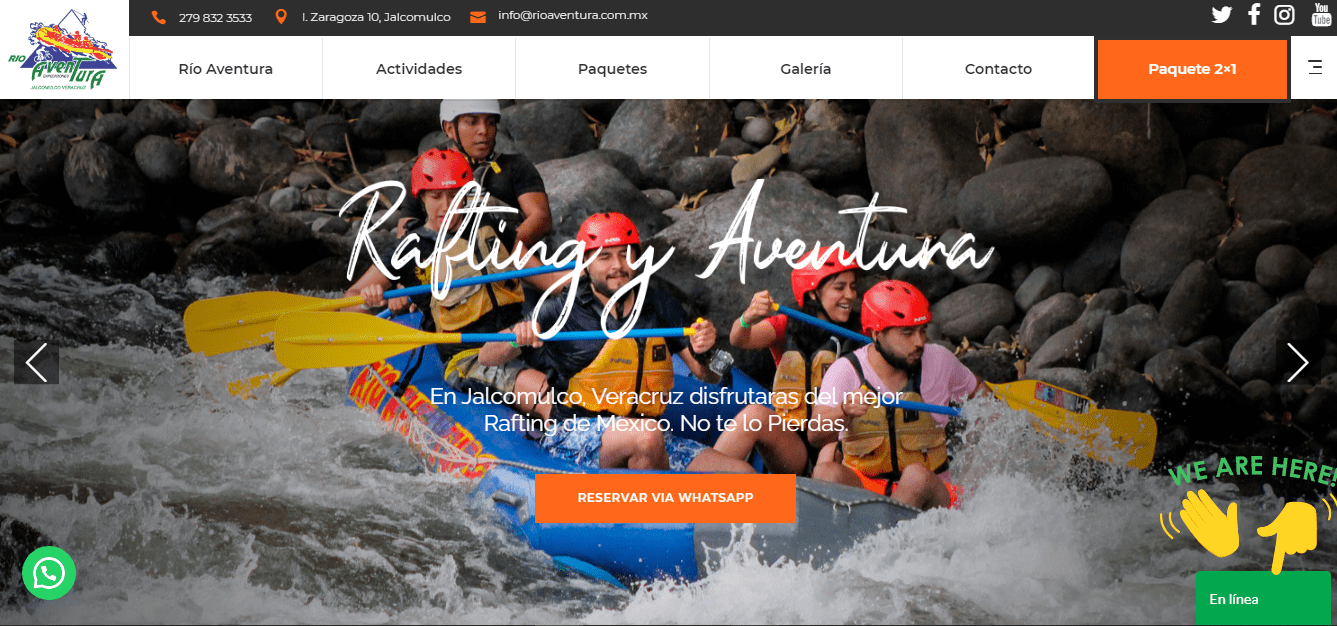
Diseño Web Rio Aventura (Desliza el Tirador)
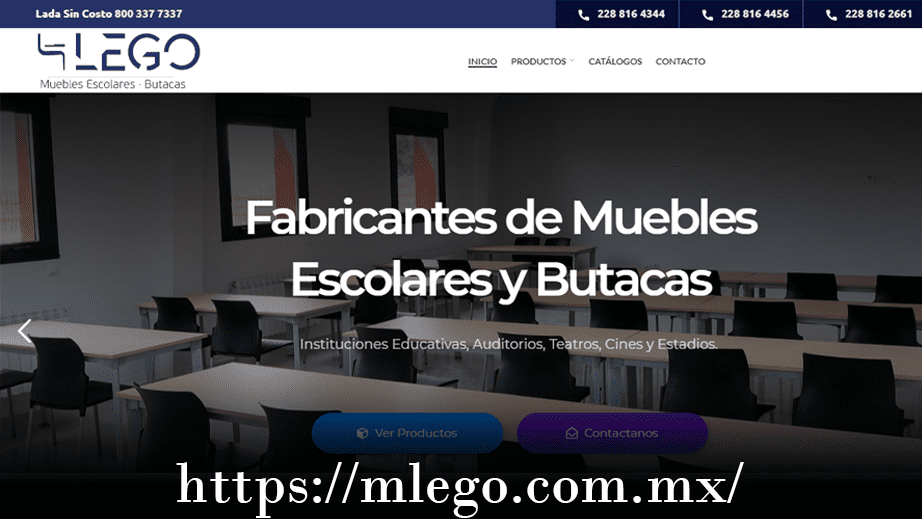
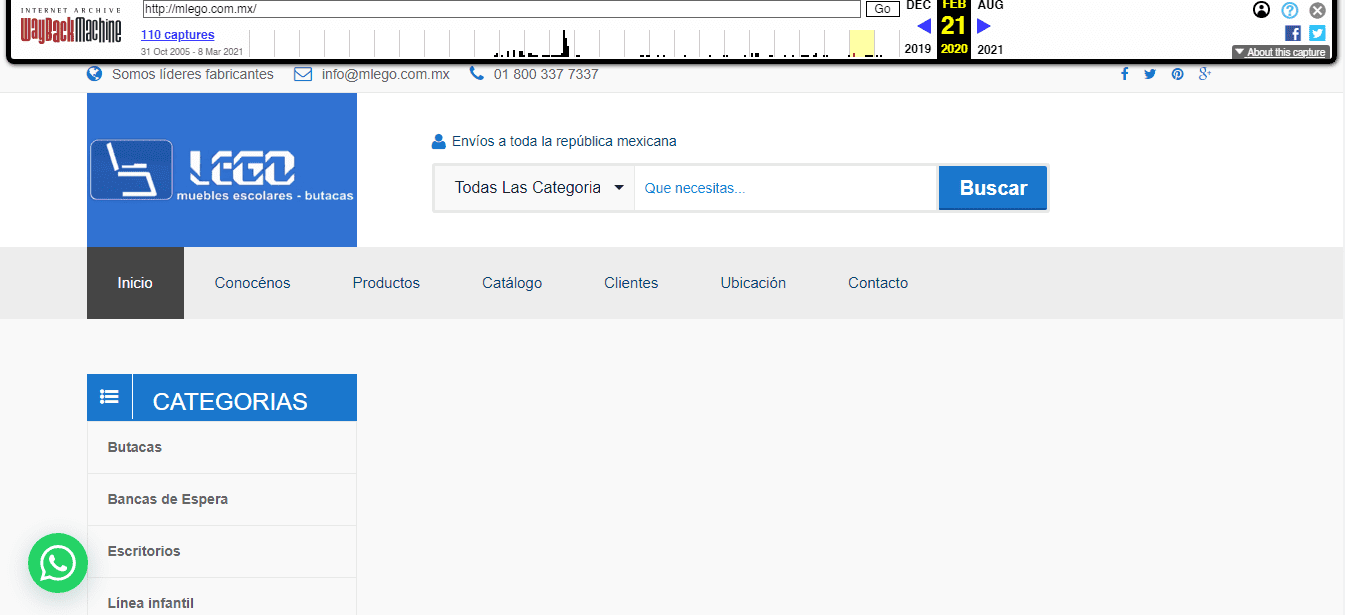
Diseño Web Muebles Lego (Desliza el Tirador)
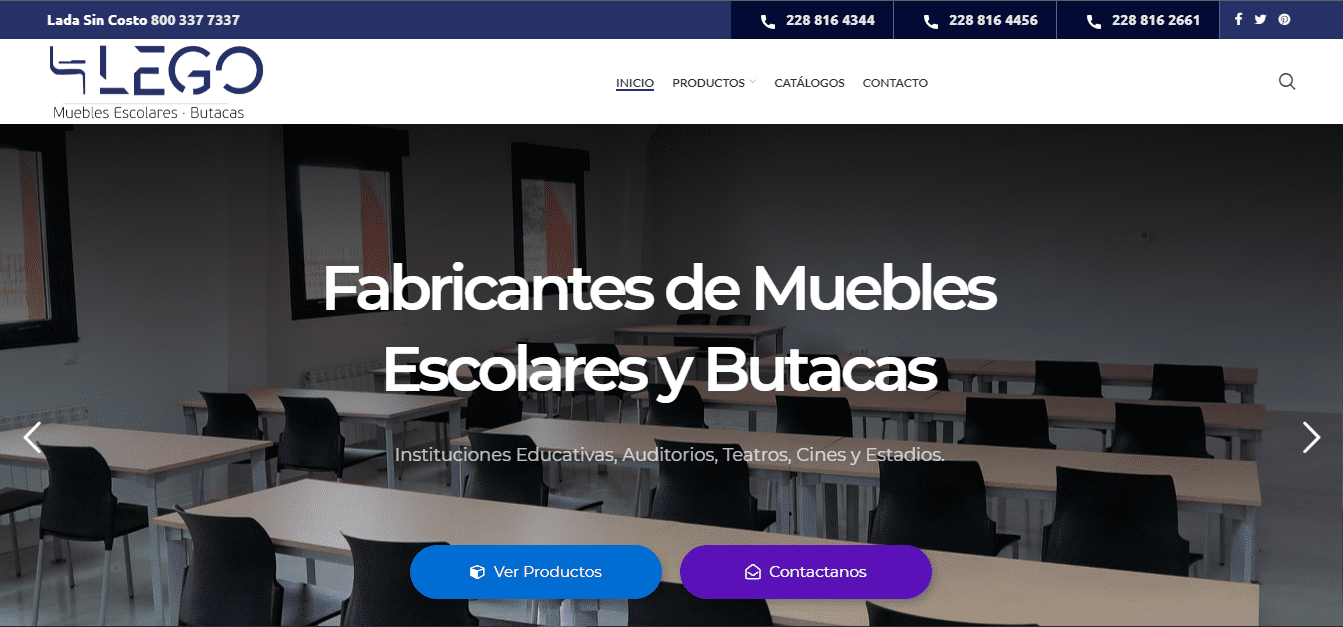
Diseño Web Desafiando Expediciones (Desliza el Tirador)

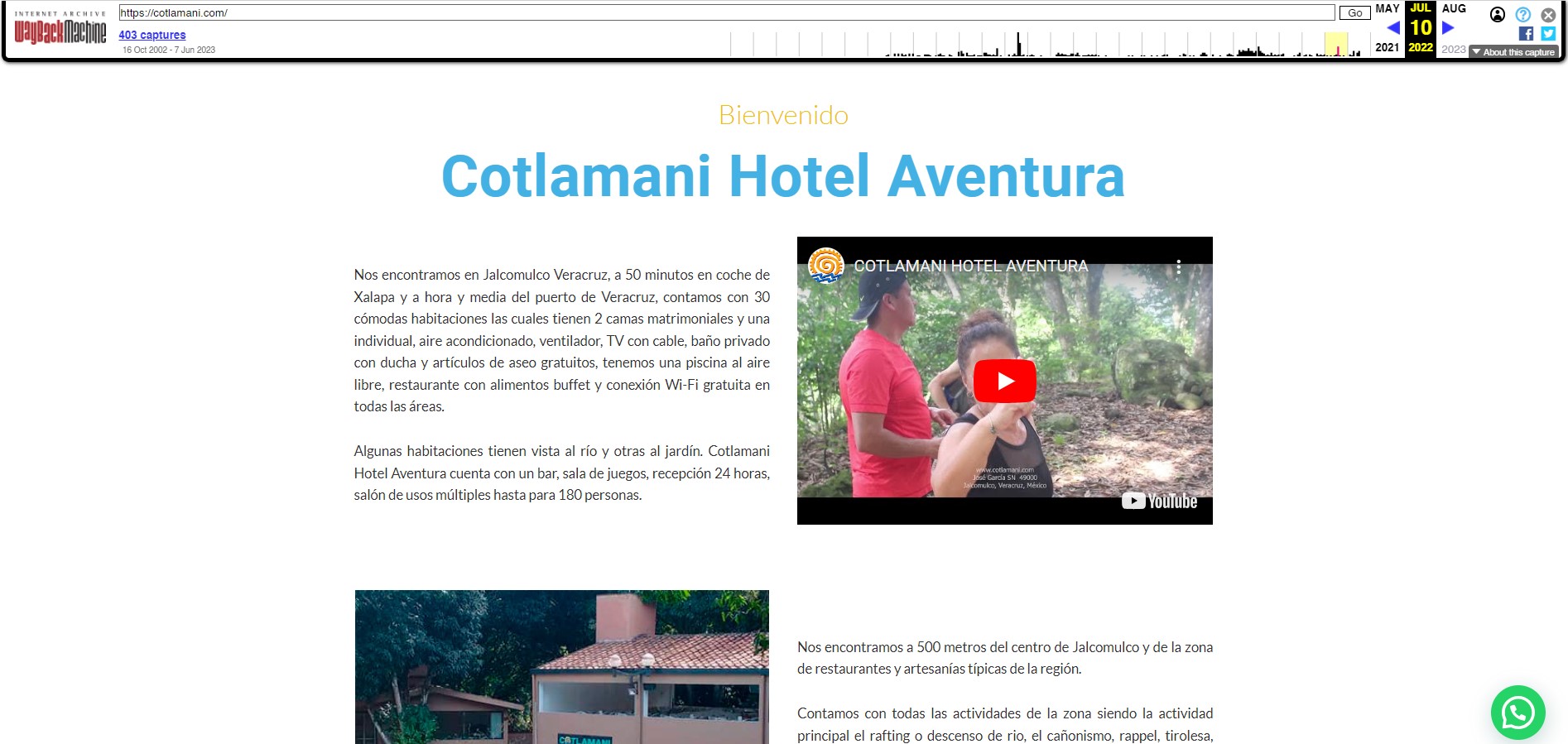
Diseño Web Cotlamani (Desliza el Tirador)

Lo que Nuestros Clientes Opinan
Diseños Web Profesionales que Ayudan a tu Negocio.
Excelentes para el diseño de páginas web, como cliente te guían a través del proyecto de principio a fin lo cual es perfecto. Se maneja una comunicación muy fácil y siempre trabajan para hacer crecer la rentabilidad de mi negocio, además de que mi sitio web es autoadministrable y fácil de manejar.
Juan Carlos Morales Hernandez
¡Servicio de Diseño Web Inmejorable!
La atención al cliente es impecable, nos ubicamos en Nautla, Veracruz, México. Siempre están cuando se les necesita, el trabajo en diseño de páginas web es genial, ya que los diseños y asesoría son la combinación perfecta, además de que el soporte es totalmente directo, muchas gracias por mi sitio web.
Rene Zorrilla
¡Excelente comunicación para el Desarrollo Web!
El diseño web fantástico y autoadministrable, sostuvimos reuniones en las oficinas de la ciudad de Xalapa, Veracruz, la comunicación fue bastante consistente y oportuna. Se propusieron ideas de ambas partes para tener en todo momento un diálogo en cada paso del proceso. El Sitio Web quedo magnífico digno de profesionales y he recibido halagos sobre él. Recomiendo ampliamente el trabajar con JuCri.
Pedro Jardines Maricalva
No lo dudes Mas y Aumenta tus Ventas ...
Cotiza Ahora el Diseño del Sitio Web que Necesitas.
Diseño de Paginas Web de Veracruz para todo México
¡Hacemos las cosas de diferente manera, así que nuestros diseños de paginas web son impresionantes! Ver Planes Web
Diseñador de Páginas Web Profesionales en Xalapa, Veracruz para Todo México.
Su sitio web es a menudo la primera cosa que sus clientes ven.
JuCri es una empresa que se ubica en el estado de Veracruz, empleamos principios de diseño sofisticados para crear la armonía perfecta entre arte y funcionalidad. Los sitios web que creamos son creativos, elegantes, estéticamente agradables y fáciles de explorar. Logrando el objetivo de, vender o dar a conocer.
Sistemas Manejadores de Contenido.
Herramienta web interactiva fácil de usar que le permite controlar el contenido de su sitio web. Somos Expertos en wordpress.
Adaptación a los Dispositivos Moviles.
Un sitio web sensible que se adapta automáticamente a la pantalla en la que se visualiza, por lo que siempre se ve bien.
Galerias Impresionantes.
Haga que el sitio web cobre vida con una galería interactiva que muestre su tienda y los servicios que ofrece.
Sitios Optimizados para los Buscadores.
Es importante para ganar tráfico a su sitio Web. Vamos a aplicar todos estos principios de SEO a su sitio.
Soporte 24 x 7 x 365
Durante y después de su proyecto, siempre estamos disponibles para su apoyo. Sea cual sea su pregunta.
Etapas para el Diseño de Paginas Web
Nuestra forma de trabajo
-
ETAPA UNO
Especificaciones del Proyecto
Definimos el diseño web del sitio, hablamos sobre las necesidades del cliente y su Idea de Negocio. (Posible Reunión Personal en el estado de Veracruz)
-
ETAPA DOS
Planeacion del Diseño Web
El diseño de tu sitio web se da por comenzado, se diseña el sitio y se muestran los avances del proyecto al cliente para que de seguimiento puntual.
-
ETAPA TRES
Programación y Publicacion
Se programa toda la funcionalidad del sitio web y se procede a la publicación del mismo en el dominio del cliente para que sea visitado.
-
ETAPA CUATRO
Mantenimiento para el Sitio
Te asesoraremos sobre como podrás realizar cambios menores en tu pagina web, si requieres cambios mayores, estaremos listos para atenderte.
Ponemos a tu disposición nuestros planes
para el desarrollo de tus Paginas Web
Diseño Web Económico / Landing Page
- Dominio .com Gratis por un año.
- Hospedaje Gratis por un año.
- Certificado SSL Gratis.
- Landing Page AUTOADMINISTRABLE.
- Diseño Web Básico Único y Original.
- Responsive Design (Adaptable a Dispositivos Móviles).
- 3 Cuentas de Correo Personalizado.
- 1 Mapa de Google Maps.
- 1 Formulario.
- 1 Botón Flotante de Whatsapp.
- Alta en 1 buscador (Google).
- Soporte Técnico Básico 24/7 Vía Mail o WhatsApp Básico.
Diseño de Pagina Web Profesional
- Dominio .com Gratis por un año.
- Hospedaje Gratis por un año.
- Certificado SSL Gratis.
- 12 Páginas/Secciones.
- AUTOADMINISTRABLE
- Diseño Web Profesional Único y Original.
- Responsive Design (Adaptable a Dispositivos Móviles).
- 50 Cuentas de Correo Personalizado.
- 1 Icono para Favoritos.
- Slider o Carrusel para su Sitio Web.
- 1 Mapa de Ubicacion de Google Maps.
- 1 Formulario de Contacto.
- 1 Botón Flotante de Whatsapp.
- Inclusion de hasta 2 Videos de Youtube.
- Chat Online.
- Alta en 3 buscadores (Google, Bing, Yahoo).
- Minicurso via Teleconferencia.
- Iconos para tu Diseño Web.
- Posicionamiento Web (SEO) Basico.
- Actualizaciones Menores 1 vez al mes por 12 meses.
- Soporte Técnico Básico 24/7 Vía Mail o WhatsApp Premium.
Diseño de Pagina Web Tienda en Linea
- Dominio .com Gratis por un año.
- Hospedaje Gratis por un año.
- Certificado SSL Gratis.
- 16 Páginas/Secciones.
- AUTOADMINISTRABLE con WooCommerce
- Diseño Web Profesional Único y Original.
- Responsive Design (Adaptable a Dispositivos Móviles).
- 150 Cuentas de Correo Personalizado.
- 1 Icono para Favoritos.
- Slider o Carrusel para su Sitio Web.
- 1 Mapa de Ubicacion de Google Maps.
- 1 Formulario de Contacto.
- 1 Botón Flotante de Whatsapp.
- Inclusion de hasta 2 Videos de Youtube por Producto.
- Chat Online.
- Alta en 3 buscadores (Google, Bing, Yahoo).
- Minicurso via Teleconferencia.
- Iconos para tu Diseño Web.
- Posicionamiento Web (SEO) Basico.
- Actualizaciones Menores 1 vez al mes por 12 meses.
- Alta de hasta 100 productos de tu Inventario a la Tienda en Linea.
- Soporte Técnico Básico 24/7 Vía Mail o WhatsApp Preferencial.
¿ Quieres ver Crecer tu Negocio ?
Comencemos TU DISEÑO Web, CONSTRUYAMOS tu IDEA, JUNTOS!